Arquiteturas de RAG: Do Clássico ao Agentic RAG, GraphRAG e CausalRAG
Guia técnico completo sobre arquiteturas de RAG: como funcionam o RAG Avançado, Modular, Agentic RAG, GraphRAG, CausalRAG, Mnemis e CAG, com benchmarks reais de custo e acurácia.


Modelos de linguagem de grande escala são, por design, máquinas de previsão estatística. Eles otimizam a probabilidade do próximo token sem nenhum mecanismo nativo de verificação factual. Isso significa que, quando a pergunta do usuário extrapola o que o modelo viu durante o treinamento, ele faz o que sabe fazer de melhor: gera uma resposta extremamente fluente, confiante e completamente errada.
Esse problema não é um bug — é uma consequência direta da arquitetura Transformer autorregressiva. E é exatamente o que torna o grounding (ancoragem de conhecimento) tão crítico em qualquer sistema de IA que pretenda operar em produção com responsabilidade factual.
A solução que o mercado e a academia consolidaram para essa lacuna se chama RAG — Retrieval-Augmented Generation (Geração Aumentada por Recuperação). Mas o RAG de 2022 não é o mesmo que precisamos hoje. As arquiteturas evoluíram de pipelines lineares simples para sistemas agênticos com capacidade de decisão autônoma, navegação por grafos de conhecimento e validação de relações causais.
Neste artigo, vou destrinchar essa evolução técnica de ponta a ponta — do RAG Naive até os paradigmas mais recentes como Agentic RAG, GraphRAG, CausalRAG e Mnemis — com dados reais de custo, latência e acurácia em produção.
Como funciona o RAG clássico
O RAG opera em duas macrofases: indexação offline e consulta online.
Indexação offline
O acervo documental bruto é carregado, fragmentado em segmentos discretos chamados chunks (blocos), convertido em vetores densos por meio de modelos de codificação (encoders) e armazenado em bancos de dados vetoriais. Cada bloco documental é projetado em um espaço vetorial de dimensão :
Consulta online
Quando o usuário faz uma pergunta, ela é projetada no mesmo espaço de representação vetorial pelo mesmo encoder, e uma busca de vizinhos mais próximos aproximados (ANN) é executada usando similaridade de cosseno:
Os chunks com maior relevância semântica são injetados no prompt do modelo como contexto factual. É importante destacar que a literatura científica demonstra diferentes modalidades de integração dessa informação recuperada: além de prompts textuais na entrada, as evidências podem se integrar como representações latentes nas camadas intermediárias de geração, modificar diretamente a distribuição probabilística dos logits na saída, ou até mesmo controlar a omissão adaptativa de etapas de decodificação.
Confiabilidade: o benchmark Trust-RAG Compass
À medida que esses sistemas entram em produção, a precisão informacional sozinha não basta. O benchmark Trust-RAG Compass (TRC Bench) avalia a confiabilidade de pipelines RAG em seis dimensões estruturadas, expondo vulnerabilidades introduzidas tanto por recuperação inadequada quanto por má utilização do conhecimento pelo gerador — fatores que frequentemente geram saídas nocivas mesmo com bases de dados curadas.
Por que o RAG clássico não é suficiente
Esse modelo linear de “recuperar e ler” (conhecido como RAG Naive) funciona em protótipos, mas apresenta falhas críticas em produção:
- Baixa precisão: chunks redundantes ou semanticamente desalinhados poluem o contexto e confundem o gerador.
- Baixa revocação: falha em recuperar evidências espalhadas em documentos com vocabulários diferentes.
- Dados obsoletos: risco de alimentar o modelo com informações desatualizadas ou alucinatórias.
A evolução das arquiteturas de RAG
O desenvolvimento dessas ferramentas seguiu uma trajetória evolutiva bem documentada na literatura de processamento de linguagem natural:
- Fundação (2020–2022): otimização estática com passagem única de dados. Treinamento conjunto encoder-gerador e recuperadores estáticos.
- Expansão (2022–2024): refinamento iterativo e formulação dinâmica de consultas. Expansão semântica e fusão híbrida (busca densa + esparsa).
- Sofisticação (2024–2025): deliberação explícita e estruturas complexas. Roteamento adaptativo, grafos de conhecimento e autoavaliação reflexiva.
Paralelamente, a topologia dos pipelines se dividiu em três fases arquiteturais: RAG Naive, RAG Avançado e RAG Modular.
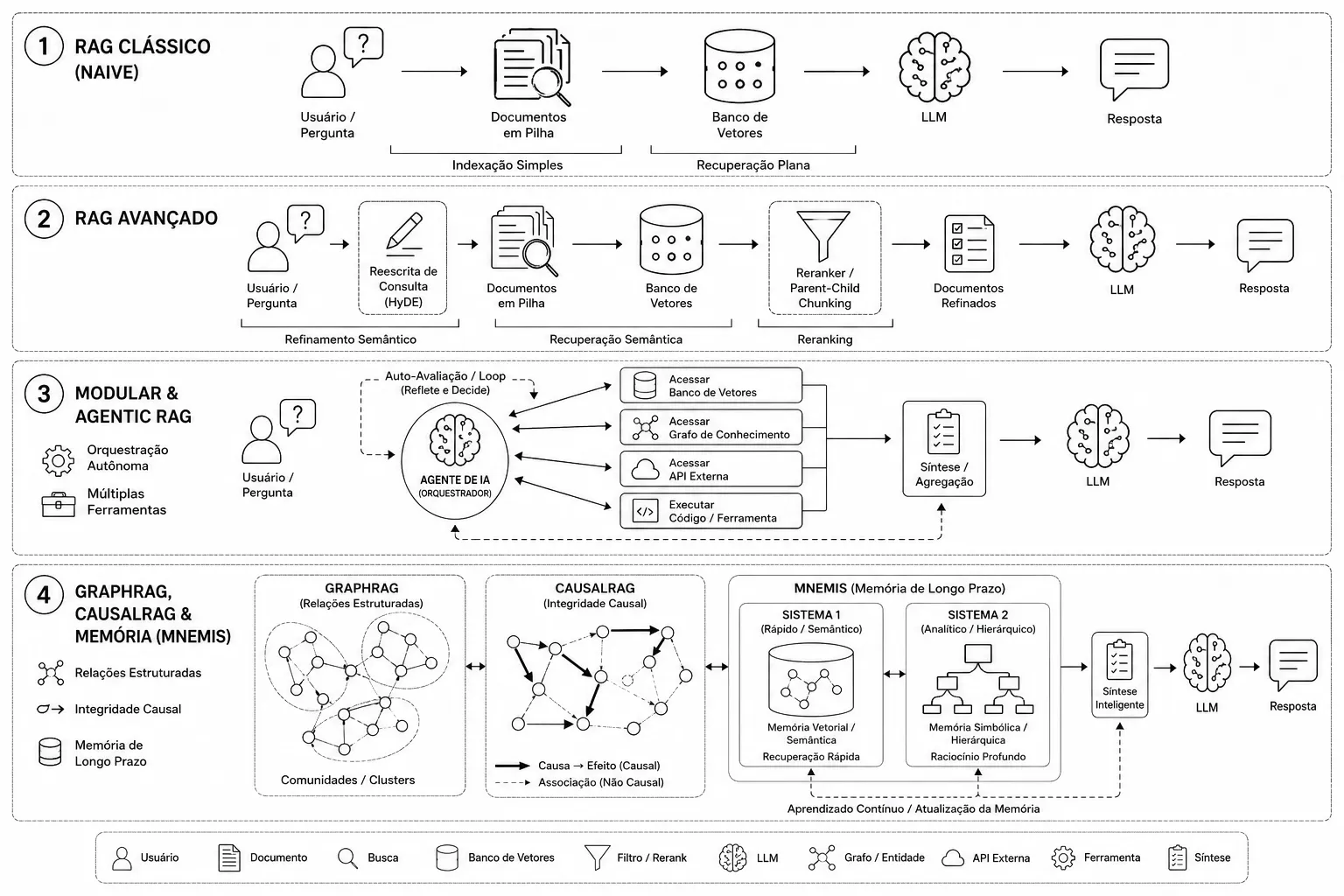
RAG Avançado: pré-recuperação e pós-recuperação
Para superar o teto de desempenho do RAG Naive, o RAG Avançado introduziu módulos especializados em duas frentes.
Pré-recuperação: reescritores de consulta e HyDE
Reescritores de consulta reformulam perguntas vagas usando interpolações semânticas ou feedback do próprio gerador, tornando a busca mais precisa.
O HyDE (Hypothetical Document Embeddings) vai além: em vez de buscar diretamente com a pergunta do usuário, o sistema primeiro gera um documento hipotético que conteria a resposta esperada e usa o vetor desse documento para realizar a busca. Isso elimina o descasamento de vocabulário entre perguntas curtas e documentos técnicos longos.
Pós-recuperação: rerankers e parent-child chunking
Cross-encoders (rerankers) recalculam a similaridade entre a pergunta e cada chunk de forma conjunta, eliminando ruídos que escapam à indexação bi-encoder.
A estratégia de parent-child chunking também se popularizou nessa fase: a busca vetorial é feita em fragmentos pequenos de alta granularidade semântica (child chunks), mas o contexto que alimenta o gerador é o bloco maior correspondente (parent chunk). Isso preserva a coesão do texto circundante e melhora drasticamente a qualidade das respostas.
RAG Modular: pipelines como grafos computacionais
A maturidade desses componentes levou ao RAG Modular, que organiza o pipeline em grafos computacionais customizáveis. O sistema é decomposto em módulos independentes coordenados por uma camada de orquestração, estruturados em quatro tipologias:
- Sequenciais: preservam a linearidade clássica com etapas adicionais de filtragem e reordenação.
- Condicionais: roteadores semânticos determinam caminhos de execução distintos com base no perfil da consulta.
- Ramificados: decomposição da pergunta em subperguntas paralelas (pré-recuperação) ou geração paralela a partir de múltiplos chunks com agregação posterior via votação (pós-recuperação).
- Em loop: circuitos iterativos entre recuperador e gerador, controlados por módulos julgadores que avaliam em tempo real se a informação recuperada é suficiente para encerrar o processo.
Agentic RAG: agentes autônomos de recuperação
Mesmo os pipelines modulares mais sofisticados operam com fluxos pré-configurados. Tarefas que exigem deliberação multifásica e decisões complexas demandam algo mais. O Agentic RAG resolve essa limitação ao colocar agentes autônomos de IA no controle do pipeline de busca.
Esses agentes utilizam padrões de design de vanguarda para gerenciar e refinar dinamicamente as estratégias de recuperação:
- Prompt Chaining: decomposição de tarefas complexas em etapas sequenciais, onde a saída de uma etapa calibra a entrada da próxima.
- Routing: direcionamento dinâmico da consulta para o repositório de dados mais especializado.
- Paralelização: divisão em buscas simultâneas (sectioning) ou geração de múltiplas respostas para consolidação via votação (voting).
- Orquestrador-Trabalhador: um agente central delega subtarefas a agentes subordinados especializados.
- Circuitos Avaliador-Otimizador: grading automático refina a precisão das saídas antes da exibição. Se o resultado for insatisfatório, o pipeline reinicia.
O framework A-RAG e suas interfaces hierárquicas de busca
O desenvolvimento mais recente dessa vertente é o A-RAG (Agentic RAG com Interfaces de Recuperação Hierárquica). Em vez de forçar o modelo a seguir um fluxo linear, o A-RAG expõe três ferramentas de granularidades distintas diretamente à camada lógica do agente:
- Busca por palavras-chave: rápida, ideal para termos exatos como códigos de erro e IDs.
- Busca semântica: baseada em proximidade vetorial, para conceitos abstratos.
- Leitura direcionada de chunks (chunk read): navegação para blocos adjacentes a partir de um fragmento já recuperado.
Isso permite que o agente atue como um pesquisador: ele faz buscas genéricas, encontra uma pista, aprofunda-se nos blocos vizinhos. Experimentos demonstram que o A-RAG supera consistentemente os métodos tradicionais usando significativamente menos tokens e escala seu desempenho de forma eficiente conforme mais recursos computacionais são concedidos na inferência (test-time compute).
Agentic RAG vs. GraphRAG vs. Workflow RAG
GraphRAG Clássico: navegação sobre grafos pré-construídos. Autonomia baixa — consome visões geradas na indexação. Flexibilidade restrita às conexões do grafo.
Workflow RAG: fluxogramas estáticos pré-definidos. Autonomia média — executa passos rígidos sequenciados. Flexibilidade limitada aos caminhos do pipeline.
Agentic RAG (A-RAG): decisão dinâmica e deliberativa orientada a metas. Autonomia alta — escolhe ferramentas e decide quando parar. Flexibilidade irrestrita — navega entre múltiplos níveis de granularidade.
GraphRAG: grafos de conhecimento para recuperação estruturada
A recuperação plana de textos ignora um fato fundamental: os conceitos em uma base documental estão conectados por relações estruturadas e hierarquias semânticas complexas. O GraphRAG resolve isso ao mapear o acervo como um grafo de conhecimento, capturando explicitamente entidades (nós) e relações (arestas). A análise prática sobre quando o uso de grafos realmente agrega valor ao RAG mostra que essa abordagem faz mais sentido quando há relações explícitas entre entidades, comunidades e dependências que o chunking puro não captura.
Como funciona a indexação do GraphRAG
Durante a indexação, entidades e relações são extraídas dos textos. O sistema agrupa essas entidades em comunidades semânticas hierárquicas usando o algoritmo de Leiden e gera resumos descritivos para cada grupo — os chamados relatórios de comunidade.
Busca global dinâmica
Para responder perguntas abstratas sobre toda a base de dados, o GraphRAG utiliza um mapa-reduzir dinâmico: partindo do nó raiz, modelos eficientes (como GPT-4o-mini) estimam a relevância de cada comunidade. Se irrelevante, o subgrafo inteiro é podado. Se relevante, o sistema desce recursivamente para os nós filhos. Esse processo reduz drasticamente os tokens processados na síntese final.
FastGraphRAG: redução de 75% nos custos de indexação
Para viabilizar a implantação corporativa sob restrições de orçamento, o FastGraphRAG substitui os LLMs na fase de extração de entidades por ferramentas tradicionais de PLN como spaCy e NLTK, usando extração gramatical e coocorrência textual. O resultado é uma redução de cerca de 75% nos custos computacionais de indexação sem comprometer significativamente a qualidade do grafo.
CausalRAG: filtrando relações espúrias com grafos causais
Grafos relacionais tradicionais ainda podem falhar ao conectar conceitos com alta similaridade semântica que são logicamente desconexos ou correlacionados por fatores espúrios. O CausalRAG aborda essa limitação ao integrar grafos causais diretamente no fluxo de busca.
Em vez de se basear apenas na proximidade de embeddings, o CausalRAG mapeia as dependências de causa e efeito presentes na documentação original. A busca avança somente por caminhos causais validados, gerando um resumo causal estruturado que filtra contradições conceituais e remove evidências enganosas baseadas em similaridade puramente linguística.
O impacto prático: as informações fornecidas ao gerador possuem integridade dedutiva contínua, reduzindo drasticamente alucinações de inferência em domínios de alta complexidade como diagnósticos industriais, análises jurídicas e pesquisa científica.
Mnemis: memória persistente dual para agentes de longo prazo
Quando o foco é construir agentes interativos com memória de longo prazo, a RAG plana top-k não é suficiente. O framework Mnemis resolve isso dividindo a memória em duas infraestruturas complementares inspiradas na teoria dos sistemas cognitivos:
- Sistema 1 (processamento rápido): um grafo base para recuperação por similaridade semântica de baixa latência — associação automática e intuitiva.
- Sistema 2 (processamento analítico): um grafo hierárquico construído bottom-up para navegação deliberativa e controle conceitual de alto nível.
Os três princípios de consistência do Mnemis
A construção da hierarquia do Sistema 2 segue três diretrizes:
- Abstração de Conceito Mínimo: cada categoria representa fielmente as características compartilhadas por seus nós filhos de forma concisa e informativa.
- Mapeamento Muitos-para-Muitos: um único nó pode pertencer a múltiplas comunidades, refletindo suas diferentes facetas conceituais.
- Restrição de Eficiência de Compactação: limites estruturais de ramificação garantem travessia eficiente da hierarquia.
Por meio de um algoritmo de seleção global descendente, o Mnemis executa buscas altamente precisas sobre a história interativa do agente, alcançando desempenho de ponta em benchmarks de memória de longo prazo.
Alternativas ao RAG tradicional: CAG, ACC e RAFT
A expansão das janelas de contexto dos LLMs modernos (1 milhão de tokens ou mais) abriu um novo debate: ainda precisamos de pipelines de recuperação em tempo real?
CAG: Cache-Augmented Generation
O CAG é uma abordagem radical. Para bases de dados estáveis e de tamanho moderado, o sistema pré-carrega todo o acervo documental na sessão do modelo durante um processamento offline. As ativações das camadas de atenção são persistidas como um KV cache (cache de chaves e valores).
Na inferência, as perguntas do usuário são computadas diretamente sobre esse estado de memória pré-computado — eliminando latência de busca vetorial, falhas de recall e toda a complexidade de manter bancos vetoriais. O desafio: reter 1 milhão de tokens em cache consome cerca de 100 GB de VRAM por sessão.
ACC: Compressão de Contexto Adaptativa
Para viabilizar o CAG em escala, a ACC utiliza estimativas de relevância e summarização hierárquica para reduzir em até 45% a ocupação de tokens na janela de contexto sem perdas perceptíveis de qualidade.
RAG Multimodal
No processamento de documentos corporativos complexos, o RAG Multimodal expande a recuperação ao tratar holísticamente textos, tabelas, gráficos e elementos de layout de página. Esse campo enfrenta debates técnicos contínuos entre abordagens baseadas em OCR e arquiteturas OCR-free, além de investigar métodos de codificação visual em alta escala e agentes focados na fusão de dados multimídia.
O modelo híbrido CAG-RAG em produção
Sistemas de produção modernos adotam o framework híbrido CAG-RAG: as consultas são processadas prioritariamente sobre o KV cache de ultra-baixa latência, mas um roteador condicional aciona buscas vetoriais tradicionais sempre que o modelo detecta incerteza lógica ou necessidade de dados atualizados.
RAFT: ensinando o modelo a ignorar ruídos
O RAFT (Retrieval-Augmented Fine-Tuning) é uma receita de pós-treinamento que prepara o modelo para cenários de recuperação imperfeita. O conjunto de dados de treino expõe o modelo a perguntas () pareadas com um bloco contendo a resposta correta () e múltiplos blocos distratores irrelevantes ().
O modelo é treinado para duas tarefas simultâneas:
- Ignorar distrações: filtrar sistematicamente o ruído dos blocos irrelevantes.
- Citar evidências: extrair sequências exatas de texto do bloco correto para justificar a resposta em formato de dedução lógica passo a passo.
Uma fração dos dados contém apenas documentos distratores, condicionando o modelo a declarar ignorância quando a evidência necessária está ausente — em vez de alucinar. O treinamento assistido por geradores de dados sintéticos como o framework BARE eleva em até 18,4% a acurácia factual comparado à sintonia fina supervisionada tradicional.
Custos, latência e acurácia em produção: dados reais
A escolha arquitetural exige uma análise criteriosa dos trade-offs de custo, latência e eficiência factual sob escala.
O impacto da janela de contexto na latência
O mecanismo de atenção dos Transformers escala de forma quadrática com o comprimento da sequência:
- RAG padrão (prompt enxuto): ~1 segundo de resposta.
- 160.000 tokens em contexto longo: ~20 segundos de processamento.
- 890.000 tokens: mais de 60 segundos por transação — inviável para chat em tempo real.
O impacto financeiro
Considerando modelos de fronteira como o GPT-4.1 (US$ 2,00 por milhão de tokens de entrada):
- Um prompt via RAG otimizado: ~US$ 0,00008 por execução.
- Uma chamada de contexto longo preenchendo 1 milhão de tokens: US$ 2,00.
- Diferença de 1.250x no custo por transação. Em escala, isso é a diferença entre viabilidade e inviabilidade econômica.
Além disso, reter 1 milhão de tokens em memória ativa consome ~100 GB de VRAM por sessão, criando barreiras severas de infraestrutura para aplicações com alto volume de acessos concorrentes.
Benchmark Databricks: acurácia vs. tamanho do contexto
Estudos da Databricks mediram a taxa de acerto factual de LLMs em diferentes comprimentos de prompt:
| Modelo | Média | 2k | 4k | 16k | 32k | 64k | 128k |
|---|---|---|---|---|---|---|---|
| GPT-4o | 0.709 | 0.467 | 0.671 | 0.752 | 0.759 | 0.769 | 0.767 |
| Claude 3.5 Sonnet | 0.695 | 0.506 | 0.684 | 0.718 | 0.748 | 0.741 | 0.706 |
| GPT-4o Mini | 0.610 | 0.424 | 0.587 | 0.649 | 0.662 | 0.648 | 0.643 |
| GPT-4 Turbo | 0.588 | 0.465 | 0.600 | 0.641 | 0.623 | 0.623 | 0.560 |
| Llama 3.1 405B | 0.550 | 0.445 | 0.591 | 0.623 | 0.594 | 0.587 | 0.426 |
| DBRX Instruct | 0.447 | 0.438 | 0.539 | 0.477 | 0.255 | — | — |
Os dados revelam padrões claros:
- A maioria dos modelos melhora ao expandir de 2k para 16k tokens (mais documentos de suporte disponíveis), mas atinge um ponto de saturação seguido de degradação.
- O DBRX Instruct sofre queda devastadora para 0.255 a partir de 32k.
- O Llama 3.1 405B atinge o pico em 16k (0.623) e degrada para 0.426 em 128k tokens.
- Apenas GPT-4o e Claude 3.5 Sonnet mantêm estabilidade factual razoável ao longo de toda a extensão — mas ainda com oscilações.
Essas degradações são intensificadas pelo viés de posicionamento “lost in the middle”: informações alocadas nas seções intermediárias de prompts longos sofrem reduções de atenção superiores a 20 pontos percentuais, gerando falhas factuais silenciosas em produção.
Diretrizes de engenharia para sistemas de produção
A conclusão prática é direta: evite arquiteturas monolíticas. A infraestrutura ideal é um pipeline híbrido com roteamento dinâmico baseado em três pilares:
1. RAG Avançado para buscas factuais localizadas
Perguntas que buscam fatos específicos e de alta frequência devem ser processadas por pipelines de RAG Avançado otimizados com parent-child chunking e reordenação por cross-encoders. Respostas rápidas, baratas e precisas.
2. GraphRAG e CausalRAG para sínteses globais
Tarefas analíticas, comparativas ou que exigem sínteses abstratas sobre todo o acervo devem ser direcionadas para GraphRAG de busca global dinâmica ou CausalRAG. A preservação das topologias causais e hierárquicas impede que o gerador elabore deduções superficiais com base em conexões semânticas fracas.
3. CAG + ACC para sessões interativas sobre bases estáveis
Repositórios compactos e altamente consultados em sessões de chat devem ser pré-carregados em KV cache com compressão adaptativa de contexto. A latência de busca cai a zero e a experiência conversacional se torna instantânea — sem os atrasos da busca vetorial em tempo real.
A escolha da arquitetura de grounding é, no fundo, uma decisão de engenharia sobre qual combinação de custo, latência e acurácia faz sentido para cada cenário específico. Não existe bala de prata. Existe o pipeline certo para o problema certo.